Paper Explained 4: Generative Adversarial Nets
Published:
GAN là một trong những framework mới và thật sự đột phá trong việc ước lượng một mô hình tạo sinh thông qua quá trình đối ngẫu. Với ý kiến cá nhân của mình thì đây là paper hay và khá phức tạp, với mình thì paper này là mô hình generative đầu tiên mà mình làm và thấy nó cũng ra gì 🤓🫰. So… Let’s dive in! Mọi người có thể tìm được paper gốc tại đây
Giới thiệu
Paper này nếu như mọi người lục lại trên arxiv thì có thể thấy nó được ra vào tháng 7 năm 2014. Theo như nhận định của các tác giả vào năm đó thì có thể thấy những mô hình deep learning thời đó cực thịnh là những mô hình discriminative (nôm na là mô hình phân loại) - là kiểu mấy cái mô hình, hiểu đơn giản là hàm ánh xạ từ một input có số chiều lớn sang một ouput có số chiều nhỏ hơn và thường phục vụ cho bài toán phân loại, ví dụ như phân loại chữ số viết tay v.v…
Và cũng thời đó, các mô hình generative (tạo sinh) thì lại có vẻ ít sôi nổi hơn (nhưng giờ thì sôi nổi rồi - 2024). Và cũng lúc này, các tác giả của paper này đã propose một framework mới, một framework hoạt động dựa trên quá trình đối ngẫu (adversarial process - mình sẽ giải thích ở phía dưới).
Main Idea: Chúng ta sẽ huấn luyện đồng thời 2 mô hình, một mô hình tạo sinh $G$ và một mô hình phân loại $D$. 2 mô hình này có vai trò khác nhau. Đối với mô hình $G$, mô hình này sẽ cố gắng ước lượng phân phối của dữ liệu. Trong khi đó đối với mô hình $D$, nó sẽ phân loại xem một sample nào đó là đến từ $G$ hay đến từ bộ dữ liệu gốc. Mong muốn của mô hình $G$ đó là cực đại khả năng mô hình $D$ đưa ra một kết luận sai (dân dã hơn là $G$ phải giỏi tới mức mà $D$ không phát hiện được sample đi ra từ $G$ là giả hay thật). Còn $D$ lúc chúng ta huấn luyện thì đương nhiên lúc nào chúng ta cũng muốn $D$ phân biệt được rồi (dân dã hơn là $D$ cũng phải đủ trình để lúc nào cũng check var được thằng e $G$). Do đó có thể thấy framework này là thuộc dạng minimax two-player game.
Như vậy, thứ mà chúng ta mong muốn trong quá trình train (theo lý thuyết) là như sau: $G$ có thể ước lượng được phân phối của bộ dữ liệu (ước lượng chính xác) và output của $D$ luôn là $0.5$.
Ý tưởng chính
Hồi này ở đoạn trên mình đã có đề cập về cái main idea của cái framework này, bây giờ mình sẽ nói cụ thể hơn (với ví dụ 👽).
Giả sử đang có 2 phe, một phe làm tiền giả (Generator 💵) và một phe làm cảnh sát (Police 👮). Phe làm tiền giả đang cố gắng làm tiền giả để qua mặt cảnh sát và lưu thông lượng tiền giả đó ngoài thị trường, còn phe cảnh sát thì lại không muốn lượng tiền giả đó lưu thông ngoài thị trường nên mới lập một team để phát hiện tiền giả. Tới đây là mọi người đã thấy có sự đối nghịch với nhau rồi, chữ Adversarial cũng từ đây mà ra.
Giờ ví dụ cuộc đụng độ này là dài vô hạn (tức là nếu không có gì tác động thì 2 bên vẫn đơm nhau). Thì ở thời điểm xuất phát ($t=0$), bên làm tiền giả tung ra một lô tiền giả, và các anh cảnh sát phải gom được cái lô đó, nhưng cái vấn đề ở đây là do đây là lần đầu tiên cả 2 làm những việc như vậy cho nên họ chưa giỏi. Như vậy, sau khi cái mấy anh cảnh sát bắt được mấy lô tiền giả, mấy anh làm tiền giả lúc này mới thấy không ổn, nên là họ cập nhật lại trình độ, rồi làm tiền giả tốt hơn. Mấy anh cảnh sát cũng không chịu để yên, lúc này mấy ảnh mới cầm cái đống tiền giả đó để học rồi xác định xem cái nào mới là giả, cái nào mới là thật, từ đó mấy ảnh phát hiện tiền giả tốt hơn.
Và cứ như vậy, cho tới một thời điểm $t = T$ với T rất lớn nào đó, phe làm tiền giả đã có đủ kỹ năng để làm tiền giả y xì đúc tiền thiệt, còn bên cảnh sát thì đã đạt tới giới hạn rồi, bởi vì nhìn tờ tiền nào cũng giống nhau (bên tiền giả làm tiền giả quá tốt) nên lúc này, kết quả tiền giả và tiền thiệt lúc nào cũng là 50%.
Toàn bộ cấu trúc của GAN sẽ là như sau:
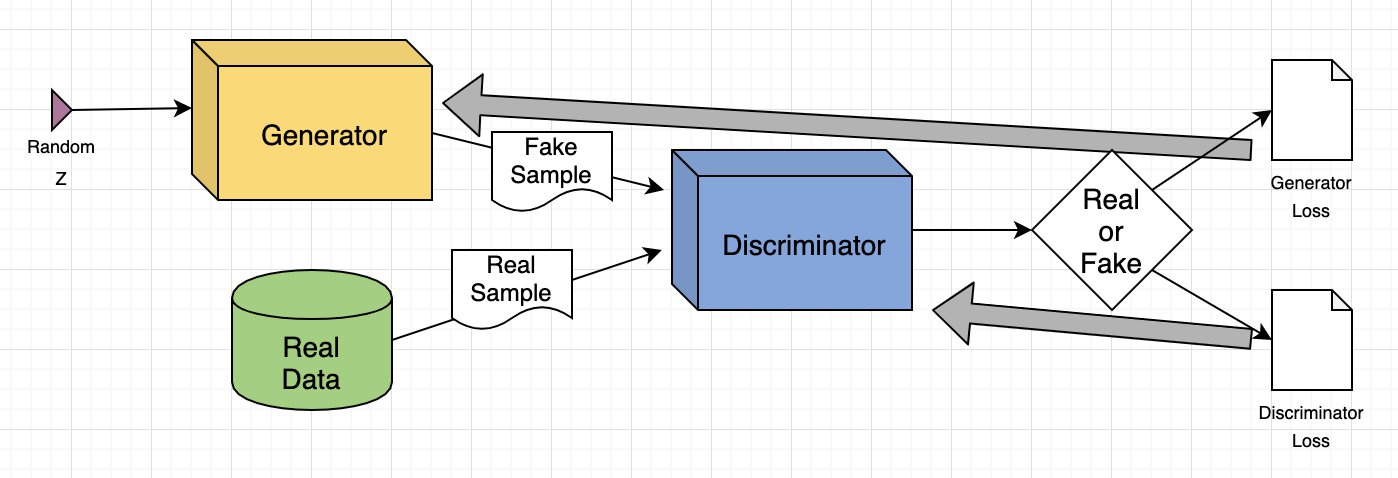
Bây giờ mình sẽ đi sâu hơn vào từng thành phần framework này.
Discriminator
Trong GAN thì phần discriminator đơn giản là một mô hình để phân loại. Main idea của phần này là phân biệt data thật và data được tạo ra bởi phần generator. Và do đây chỉ là cái tên thôi, nên về cơ bản mọi người sử dụng network nào cũng được, CNN, MLP, v.v… (trong bài gốc thì các tác giả chọn cái MLP) miễn mọi người thiết kế sao cho nó thực hiện được tác vụ của nó là ok.
Dữ liệu huấn luyện của Discriminator
Như cái hình ở trên đã thể hiện, nguồn dữ liệu để train phần Discriminator đến từ 2 nguồn:
- Dữ liệu thật ($X$): Nó như cái tên gọi luôn ._. từ chính bộ dữ liệu thật 😐
- Dữ liệu giả ($G(\mathbf{Z})$): Dữ liệu này được sinh ra từ phần Generator với input là một vector nhiễu.
Quá trình huấn luyện của Discriminator
Trong quá trình huấn luyện Discriminator, chúng ta không huấn luyện phần Generator. Đây là mọt ý rất quan trọng, trọng số của $G$ được giữ nguyên để tạo sample cho Discriminator huấn luyện trên đó.
Như trong cái hình của phía trên, có thể thấy phần Discriminator liên quan đến 2 hàm loss chính. Trong quá trình huấn luyện Discriminator thì nó sẽ bỏ qua phần loss của Generator (tức là nó chỉ dùng loss của nó thôi). (Mọi người lưu ý phần này bởi vì huấn luyện Generator sẽ hơi khác.)
Trong quá trình huấn luyện phần Discriminator:
- Phần Discriminator sẽ phân loại ảnh thật và ảnh giả từ các nguồn của nó.
- Hàm loss của phần Discriminator sẽ “phạt” phần Discriminator nếu nó phân loại sai (nếu như sample đó là ảnh real mà Discriminator kêu là ảnh fake, vice versa).
- Phần Discriminator sẽ tự cập nhật trọng số của nó thông qua lan truyền ngược từ cái Discriminator loss.
Generator
Trong GAN, phần Generator được huấn luyệnd để tạo ra dữ liệu giả bằng cách phối hợp feedback từ discriminator (phần ý tưởng mình có đề cập nhóm trộm sẽ học cách làm tiền giả tốt hơn, idea của từ feedback trong ý này cũng là cái đó). Objective của phần Generator là huấn luyện sao cho lừa được cái Discriminator, tức là làm cho cái Discriminator phân loại cái hình đó là thật.
Việc huấn luyện Generator có nhiều yêu cầu chặt chẽ hơn khi so với huấn luyện phần Discriminator, nó bao gồm các ý dưới đây: (Google)
- Đầu vào ngẫu nhiên
- Mạng Generator (cái gì cũng được, tác giả propose dùng MLP thuần túy)
- Mạng Discriminator
- Output của Discriminator
- Generator Loss (idea tương tự như hàm loss của Generator, tức là nếu mạng Generator không lừa được cái Discriminator thì nó sẽ bị phạt).
Đầu vào của Generator
Các tác giả propose chúng ta sử dụng một cái random vector để làm input cho mô hình, mà cụ thể hơn, trong paper thì các tác giả đề xuất các vector nhiễu này sẽ tuân theo phân phối đồng nhất (Uniform Distribution). Phần Generator sẽ ánh xạ cái input này sang một cái output có ý nghĩa, lí do cho việc chúng ta sử dụng noise làm input đó là để GAN có thể đa dạng dữ liệu sinh ra từ G hơn (đương nhiên là vẫn trong cái phân phối mà chúng ta muốn cái Generator tái hiện).
Nhưng mà theo như paper, họ nói là có nhiều thí nghiệm được thực hiện và họ thấy rằng phân phối của nhiễu là không quan trọng lắm, nên là chúng ta nên chọn cái gì mà chúng ta dễ dàng lấy mẫu được, ví dụ là lấy từ một phân phối đồng nhất. Cụ thể hơn ý mình, goal của mình là tái hiện được cái phân phối của bộ dữ liệu, tức là $ \mathbf{x} = G(\mathbf{z})$ là mong muốn của mình, nên là lúc này thì $\mathbf{z}$ có tuân theo phân phối gì thì sau khi ánh xạ sang domain của $\mathbf{x}$ thì nó cũng không chắc là sẽ giữ được cái phân phối ban đầu.
Điều mình vừa nói ở trên là trong cái hình này:
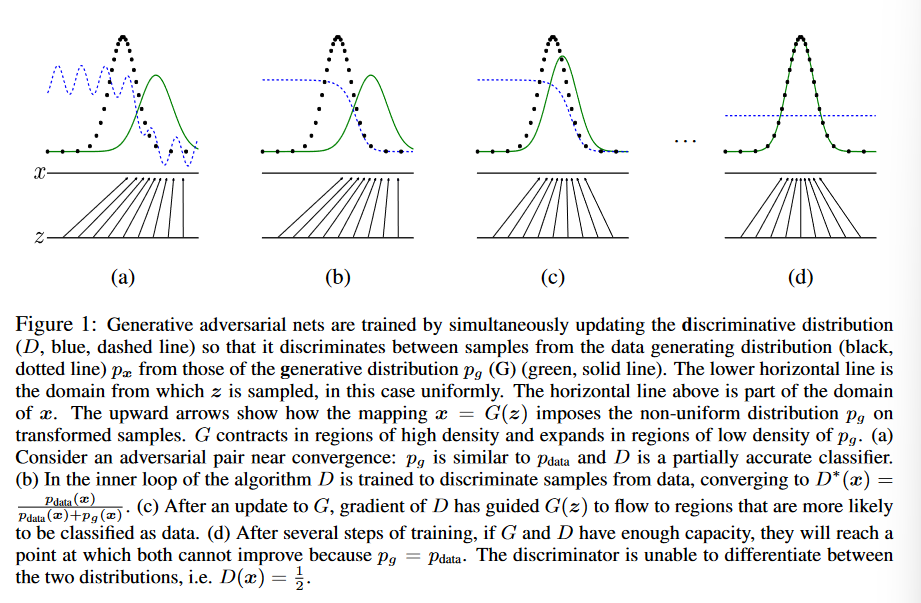
Và để cho thuận tiện thì số chiều của cái vector nhiễu này thường nhỏ hơn chiều của output của mô hình (ví dụ trong bài này, thì số chiều của vector là thuộc $\mathbb{R}^{100}$, còn của output của Generator là một cái hình thuộc $\mathbb{R}^{28 \times 28}$)
Sử dụng Discriminator để huấn luyện Generator
Như cái hình ở trên về cấu trúc của GAN, vấn đề của cái Generator đó là nó không trực tiếp liên quan tới cái hàm loss mà chúng ta muốn thay đổi (chúng ta muốn thay đổi cái kết quả output của cái Discriminator), nhưng mà cái Discriminator lại chịu ảnh hưởng của cái Generator.
Và do đó, muốn từ cái output đó, mà chúng ta chỉnh lại các tham số của phần Generator, chúng ta sẽ cần phải tính thêm ảnh hưởng của cả phần Discriminator. Như vậy thì quá trình lan truyền ngược sẽ bắt đầu từ cái output và chảy ngược về phần Discriminator, sau đó chảy ngược lại về phần Generator. Và đương nhiên cũng như phần Discriminator, chúng ta không muốn Discriminator cũng bị cập nhật lại tham số trong quá trình huấn luyện phần Generator này, nên chúng ta sẽ freeze nó lại.
Quá trình huấn luyện của Generator.
- Lấy ngẫu nhiên một vector nhiễu
- Tạo ra output từ vector nhiễu đó
- Phần Discriminator sẽ xác định thật hay giả từ cái output vừa tạo ở bước 2
- Tính toán loss của phần Discriminator
- Lan truyền ngược về cả Discriminator và Generator để có được giá trị gradients
- Sử dụng gradient để thay đổi trọng số của của Generator.
Và đó là các thực hiện một vòng lặp huấn luyện cho phần Generator.
Quá trình huấn luyện GAN
Có thể thấy GAN có 2 thành phần chính ở trên với objective khác nhau cũng như cách thức train khác nhau, do đó khá khó để cài đặt sao cho phù hợp (các vấn đề sẽ được đề cập sau) (mà thật ra thì cài đặt những cái liên quan đến Game Theory thường khó 😐). Không chỉ vậy, sự khó nhằn còn nằm ở vấn đề hội tụ của mô hình, nó không đơn giản như kết quả tối ưu cực đại mình đề cập ở trên ($p_G = p_{data}$ và $D_G(\mathbf{z}) = 0.5$).
Phương pháp huấn luyện GAN
Với 2 phương pháp huấn luyện khác nhau, việc train toàn bộ GAN cùng một lúc có thể được thay thế bằng quy trình như sau:
- Huấn luyện Discriminator với 1 hoặc vài epoch
- Huấn luyện Generator với 1 hoặc vài epoch
- Lặp lại bước 1 và bước 2 tới khi hội tụ
Và phải nhớ rằng trong lúc huấn luyện 1 thành phần, ta giữ thành phần còn lại cố định
Vấn đề về tính hội tụ
Mục trên có đề cập về vấn đề cài đặt sao cho phù hợp. Có thể hiểu rằng phần Generator sẽ được cải thiện trong quá trình huấn luyện, và phần Discriminator sẽ luôn có performance kém hơn bởi vì phần Generator làm tốt hơn. Và trong trường hợp tối ưu toàn cục như ở trên (generator cho ra output giả trông y xì real data, còn discriminator cho ra kết quả như đánh gacha) đã lòi ra một vấn đề chính khi train tổng thể mô hình GAN.
Vấn đề nằm ở chỗ phần feedback của Discriminator trở nên kém ý nghĩa hơn nếu quá trình train cứ tiếp tục diễn ra (bởi vì nó không còn tốt khi so với phần Generator quá siêu việt nữa). Và rồi đến một lúc nào đó, những cái tín hiệu phản hồi của Discriminator trở nên vô nghĩa (và cái Generator đó học theo cái tín hiệu vô nghĩa đó), phần nào đó sẽ làm giảm đi tính hiệu quả của phần Generator.
Tổng kết lại thì quá trình huấn luyện của GAN có thể được tóm tắt bằng hình dưới đây:
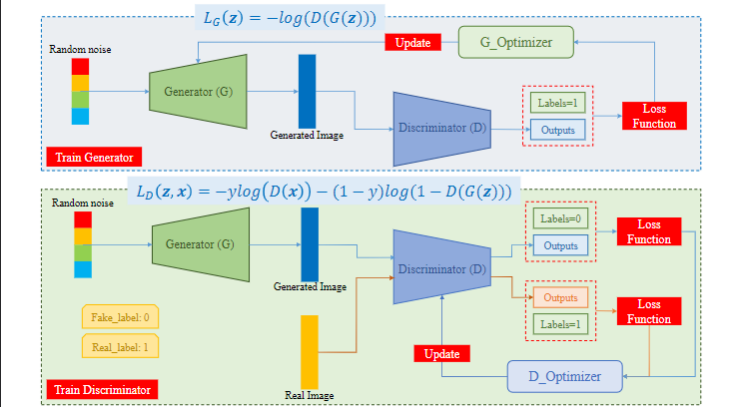
Các thành phần của hàm Loss sẽ được giải thích ở phía dưới.
Hàm Loss
Như trong cái hình đầu tiên, có thể thấy có 2 hàm loss, ám chỉ GAN sẽ sử dụng 2 hàm loss riêng biệt. Một hàm loss được sử dụng cho Generator và một hàm loss được sử dụng cho Discriminator. Quan trọng ở đây là 2 hàm loss này phải làm việc cùng nhau để phán ánh độ đo về khoảng cách của 2 phân phối xác suất.
Trong paper của GAN, $D$ và $G$ đóng vai trò là hay người chơi trong một trò chơi minimax với hàm giá trị $V(G,D)$ như trong công thức sau:
\[\begin{equation} V(G,D) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] \end{equation}\]Trong đó:
- $D(x)$: Ước lượng xác suất của Discriminator cho một dữ liệu thật là thật.
- $E_x$: Giá trị kỳ vọng trên toàn dữ liệu thật.
- $G(z)$: Output của phần Generator với nhiễu z được sampling từ $p_z$
- $D(G(z))$: Ước lượng xác suất của Discriminator cho một dữ liệu giả là thật.
- $E_z$: Là giá trị kỳ vọng trên tất cả input nhiễu của Generator, qua đó, cũng là giá trị kỳ vọng trên toàn dữ liệu giả được tạo ra từ $G(z)$.
Với công thức ở trên, có thể thấy rằng không có cách nào để phần Generator có thể ảnh hưởng trực tiếp lên $\log(D(x))$, do đó mà với phần Generator, tối thiểu hàm loss ở trên cũng đồng nghĩa với việc tối thiểu $\log (1 - D(G(z)))$ .Tuy nhiên trong thực nghiệm, phương trình trên không phù hợp cho đạo hàm của $G$ để nó học tốt. Bởi vì thử tưởng tượng, ở những giai đoạn đầu của quá trình huấn luyện, những gì $G$ nhả ra là một cái output ngẫu nhiên nào đó, do đó $D$ luôn có thể dễ dàng detect được. Trong trường hợp này, $\log (1 - D(G(z)))$ trở nên bão hòa. Do đó mà thay vì huấn luyện $G$ theo cái objective ở trên, ta cũng có thể huấn luyện $G$ để tối đa giá trị của $\log(D(G(z)))$. Cách thức thay đổi này cho phép cung cấp nhiều thông tin cho $G$ hơn trong giai đoạn đầu của quá trình huấn luyện.
Cụ thể hơn trong GAN, hàm Loss của Generator với đầu vào $\mathbf{z}$ là như sau:
\[\begin{equation} L_G(\mathbf{z}) = -\log(D(G(\mathbf{z}))) \end{equation}\]Trong khi đó, hàm Loss của Discriminator với 2 source data khác nhau ($\mathbf{z,x}$) là như sau:
\[\begin{equation} L_D(\mathbf{z,x}) = -y\log(D(\mathbf{x})) - (1-y)\log(1-D(G(\mathbf{z}))) \end{equation}\]Code
Ở đây thì mình sẽ thực hiện trên bộ MNIST (bộ này nhẹ, và có hàm để gọi thẳng luôn).
Những cái phần như là setup data hay gì gì đấy thì mình tạm bỏ qua, mình sẽ tới những phần quan trọng đó là phần mô hình và cách thức huấn luyện.
Đầu tiên là cách thiết kế Generator và Discriminator. Các tác giả propose sử dụng mạng MLP nên mình cũng sẽ sử dụng các mạng MLP.
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.BatchNorm1d(256,),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Descriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
Về hàm loss thì cả 2 thành phần đều sử dụng Binary Cross Entropy Loss, bên cạnh đó thì mình sẽ sử dụng Adam Optimizer (vì mình thích chứ trong paper người ta dùng các phương pháp cập nhật theo kiểu gradient-based khác, cụ thể là momentum).
EPOCHS = 200
K = 3
optimizer_G = torch.optim.Adam(generator.parameters(), lr=0.0001)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=0.0002)
criterion = nn.BCELoss()
hist = {
"train_G_loss": [],
"train_D_loss": [],
}
for epoch in range(EPOCHS):
running_G_loss = 0.0
running_D_loss = 0.0
for i, (imgs, _) in enumerate(dataloader):
real_imgs = imgs.to(device)
real_labels = torch.ones(imgs.shape[0], 1).to(device)
fake_labels = torch.zeros(imgs.shape[0], 1).to(device)
# Noise input for Generator
#z = torch.randn((imgs.shape[0], latent_dim)).to(device)
# --- Train Discriminator ---
for step in range(K):
optimizer_D.zero_grad()
# Generate a batch of images
z = torch.randn(imgs.shape[0], latent_dim).to(device)
fake_imgs = generator(z)
# Real images
real_loss = criterion(discriminator(real_imgs), real_labels)
# Fake images
fake_loss = criterion(discriminator(fake_imgs), fake_labels)
# Total loss
D_loss = (real_loss + fake_loss) / 2
if step==K-1:
running_D_loss += D_loss.item()
else:
continue
D_loss.backward()
optimizer_D.step()
# --- Train Generator ---
optimizer_G.zero_grad()
fake_imgs = generator(z)
G_loss = criterion(discriminator(fake_imgs), real_labels)
running_G_loss += G_loss.item()
G_loss.backward()
optimizer_G.step()
epoch_G_loss = running_G_loss / len(dataloader)
epoch_D_loss = running_D_loss / len(dataloader)
print(f"Epoch [{epoch + 1}/{EPOCHS}], Train G Loss: {epoch_G_loss:.4f}, Train D Loss: {epoch_D_loss:.4f}")
hist["train_G_loss"].append(epoch_G_loss)
hist["train_D_loss"].append(epoch_D_loss)
if epoch % save_interval == 0:
save_image(fake_imgs.data[:25], f"images/epoch_{epoch}.png", nrow=5, normalize=True)
Trong paper các tác giả có nói rằng họ sẽ sử dụng $k$ bước để tối ưu phần Discriminator và $1$ bước để tối ưu phần Generator (mỗi một minibatch). Điều này cho phép các trọng số của phần Discriminator nằm gần kết quả tối ưu (miễn là phần Generator thay đổi từ từ). Và trong paper, các tác giả sử dụng k = 1.
Kết quả thuật toán
Với bộ dữ liệu MNIST khi train trên tổng cộng gần 200 epoch thì ta sẽ có như sau:
Đầu tiên, tại bước khởi tạo của Generator, khi chúng ta cho vào input là một cái random vector thì output lúc này nhìn chẳng ra cái gì cả, như hình dưới đây

Sau đó, train với khoảng 50 epoch, ta được kết quả như dưới đây:

Và cuối cùng, train với khoảng 190 epoch, ta được kết quả như hình:

Và với mong đợi của chúng ta, chúng ta mong muốn phần Generator của GAN phải làm tốt, cũng tức là giá trị loss của Generator phải giảm, nhưng đồng thời, để Generator làm tốt, đồng nghĩa với việc Discriminator không còn đủ khả năng để ngang hàng với Generator nữa, cho nên loss của Discriminator phải tăng. Mọi người có thể quan sát kĩ hơn trong code này.
Và như lúc nãy chúng ta đã đề cập, loss của phần Discriminator, đẹp nhất, nên nằm ở mức 0.5 hoặc xấp xỉ, tức là lúc này, phần Discriminator phải không phân biệt được đâu là ảnh thật, còn đâu là ảnh giả, lúc này, xác suất để Discriminator đưa ra kết quả đúng không khác gì trò chơi may rủi.
Tuy nhiên cũng phải lưu ý thêm, việc đánh giá GAN bằng loss là chưa đủ. Bởi vì suy cho cùng, ta muốn những hình ảnh tạo ra bởi cái Generator một phần nào đó, phải đẹp nữa, do đó mà trong trường hợp của chúng ta, loss có thể là một thước đo chưa phù hợp.
Ưu và nhược điểm của framework
Ưu điểm:
- Khả năng học không giám sát: GANs có thể học để tạo ra dữ liệu mà không cần nhãn, điều này mở ra khả năng ứng dụng trong nhiều lĩnh vực mà dữ liệu có nhãn là khan hiếm.
- Ứng dụng đa dạng: Từ việc tạo ảnh, video giả mạo đến việc tạo dữ liệu huấn luyện cho các mô hình khác, GANs đã mở ra nhiều hướng ứng dụng mới trong AI (như mình đã nói, GAN giống như là một framework sử dụng quá trình đối ngẫu, chứ không phải đơn thuần chỉ là một mạng nào đó.)
Nhược điểm:
- Khó huấn luyện: Việc cân bằng giữa mô hình sinh và mô hình phân biệt là một thách thức lớn, dễ dẫn đến tình trạng mô hình không hội tụ. Do đó mà chúng ta cần phải cân nhắc thật kĩ trước khi đặt tay vào code, bởi vì nhiều tình huống có thể xảy ra như mình nói ở trên (ví dụ như Discriminator thống trị luôn phần Generator)
- Mode collapse: Đây là hiện tượng mà mô hình sinh chỉ tạo ra một số lượng hạn chế các mẫu, làm giảm đa dạng của dữ liệu được tạo ra. Mọi người có thể thấy điều này trong epoch thứ 190 ở trên, các tham số của Generator đã hội tụ ở nơi mà nó lừa được Discriminator, và về một mức độ nào đó thì kết quả đó an toàn, nhưng nhạt.
Thảo luận thêm.
Về phần thảo luận thêm, các tác giả có đề xuất trong paper rồi nên mình cũng không biết nói gì ._. Nhưng cá nhân mình thấy kết hợp game theory vào deep learning cũng rất sáng tạo =)))))))))))) nói chung là hứng thú.
Chắc cũng phải kiếm thêm vài cái để cài lại cho đỡ chán : D
Reference
1: AWS - https://aws.amazon.com/vi/what-is/gan/
2: Google - https://developers.google.com/machine-learning/gan/generator
3: AIO