Fundamental 1: Loss function
Published:
Blog này sẽ giới thiệu về các hàm loss (error function hoặc loss function) được sử dụng trong Machine Learning & Deep Learning. Hàm loss trên đời thì nhiều vô kể, với mình, hàm loss chỉ cần đạt đủ tiêu chí để nó trở thành một hàm loss, thì nó sẽ là một hàm loss. Ok, mời mọi người đọc
0. Danh mục:
Trong trường hợp bài viết này trở nên quá dài (và table of content không hoạt động, sr 🥹)
1. Giới thiệu
TLDR: Hàm loss là một hàm toán học giúp hỗ trợ đo lường hiệu quả hoạt động giữa dự đoán của mô hình và giá trị thực tế (có nhiều thước đo hiệu quả hoạt động khác nhau như là thời gian inference, hoặc là nếu mà xét tới các services thì sẽ là thời gian hồi phục sau sự cố, v.v… Nói chung là tùy vào objective của người thiết kế).
Xét trong lĩnh vực học máy, hàm loss hoạt động như là một kim chỉ nam giúp điều hướng quá trình huấn luyện mô hình đạt tới kết quả tối ưu cho các objective của mô hình (Objective mình không biết dịch ra tiếng việt là sao, nhưng mà có thể hiểu nó như là mục tiêu mình nhắm tới, lấy ví dụ như mấy bạn muốn sai số dự đoán là nhỏ nhất, lúc này objective của mọi người, cái mục tiêu của mọi người là giá trị mất mát đó trở nên nhỏ nhất, hoặc hiểu theo cách khác là mô hình dự đoán đúng nhất). Và do đó, một hàm loss sẽ mang các tính chất sau:
Đo lường hiệu quả hoạt động: Đây là một tiêu chí thấy rõ khi mà chúng ta cân nhắc hiệu quả hoạt động của các mô hình, trong quá trình học tập, chúng ta mong muốn mô hình phải có loss càng nhỏ càng tốt. Nó giống như các bạn đi làm bài kiểm tra á, hầu hết bạn nào cũng muốn mình được điểm cao, đồng nghĩa với việc các bạn làm sai ít đi, mà để các bạn làm sai ít đi, thậm chí không sai càng tốt, thì câu trả lời của các bạn (gọi là prediction) và câu trả lời trên cái đáp án (ground truth hoặc là label) nó phải càng sát càng tốt, nó đúng luôn càng vui.
Kim chỉ nam: Lấy tiếp cái ví dụ ở trên, giờ ví dụ các bạn đéo học gì hết á, thì điểm các bạn sao cao được, nên là lúc mà có đáp án, lúc mà đối chiếu câu trả lời của các bạn với đáp án, các bạn biết mình sai ở đâu, cần sửa ở đâu thì các bạn sẽ sửa ở đó (quá trình mà các bạn sửa như thế nào thì đó là một câu chuyện khác, chắc là sẽ làm một blog khác). Tương tự cho các bài toán học máy, mô hình sau khi dự đoán sai thì sẽ biết nó sai ở chỗ nào để mà sửa cho kết quả tốt hơn.
Điều chỉnh hành vi: Lấy tiếp cái ví dụ ở trên, giờ vô phòng thi, lấy ví dụ thi bằng lái đi ha, nó có mấy câu điểm liệt, mấy bạn lệch pha mấy câu đó là mấy bạn liệt luôn, nên là trong trường hợp của các bạn, có những lỗi sai nặng nề hơn những lỗi sai khác, do đó các bạn phải xử lý để không sai các lỗi chí tử, tức là lúc này, objective của các bạn sẽ có sự điều chỉnh, hàm loss của các bạn sẽ giúp điều chỉnh.
Cân bằng: Cân bằng ở đây có nghĩa là cân bằng giữa bias và variance, cho phép mô hình tổng quát hơn. Quay lại cái ví dụ ở trên, một học sinh tốt là một học sinh không học vẹt và không học ngu. Học vẹt ở đây ví dụ như các bạn gặp rồi các bạn mới làm được, còn các bạn không gặp là các bạn tịt luôn (dù là cùng 1 dạng bài, đổi số thôi). Học ngu ở đây là các bạn chả hiểu gì, vô các bạn chọn toàn C (do các bạn thấy cái này có xác suất đúng cao, chứ các bạn không hiểu sao nó cao vậy), lúc này các bạn cũng cúc.
Một hàm loss cơ bản theo mình cần đáp ứng 2 tiêu chí đầu, một hàm loss tốt sẽ đáp ứng tốt 4 tiêu chí. Cụ thể hơn có thể xem cái hình dưới đây:
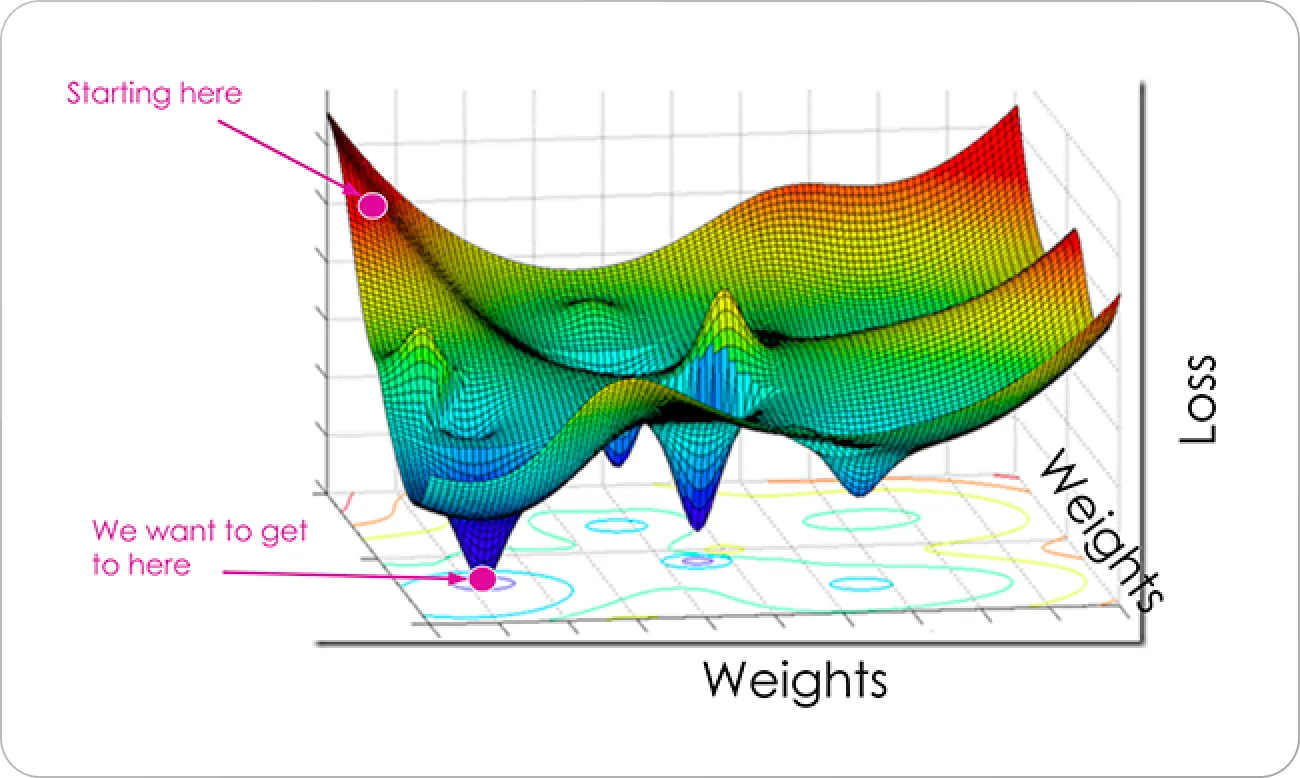
Trên cái trục loss, ở giá trị càng cao, càng tệ (hầu hết là vậy), do đó mà ở lúc mới đầu, có thể nói hiệu quả hoạt động mô hình chưa tốt, do đó mà mình cần điều chỉnh. Nhưng câu hỏi là phải đi theo hướng nào bây giờ, vì không phải cứ muốn nó đi là nó đi, do đó với một hàm loss được thiết kế, mô hình sẽ điều chỉnh tham số sao cho nó đi theo hướng làm loss nhỏ hơn. Đó, cứ làm như vậy đủ nhiều là chúng ta sẽ có một mô hình tốt (hy vọng vậy). Nhưng hàm loss tốt, sẽ giúp các bạn xuống điểm loss ở tận cùng luôn, còn một hàm loss chưa tốt thì chưa làm được việc đó, quay trở lại với ý “hướng làm hàm loss nhỏ hơn”, có nhiều hướng làm giá trị loss nhỏ hơn, nhưng một hàm loss tốt sẽ đưa ra hướng làm giá trị loss nhỏ nhất. Cơ bản là vậy ha.
2. Các hàm loss phổ biến
Trong học máy, các hàm loss thường được xắp sếp theo các bài toán mà nó đang giải quyết, do đó mà hầu hết nó rơi vào 2 dạng toán là hồi quy hoặc phân loại (các trường hợp đơn giản). Ở mức cơ bản, các bài toán hồi quy thường cho ra giá trị dự đoán là một số thực, trong khi đó các bài toán phân loại thì cho ra giá trị là các nhãn rời rạc.
2.1 Tiêu chí chọn hàm loss
TLDR: Hàm loss mà bạn chọn phải cùng chí hướng với objective mà bạn muốn nó giúp bạn đạt được. Ngoài ra không phải cứ muốn chọn hàm loss nào cũng được, sẽ có nhiều hàm loss ảnh hưởng bởi outlier, có nhiều hàm khác thì lại không chịu ảnh hưởng đó.
Các bạn phải để ý tới công thức toán học cũng như là ý nghĩa đằng sau những công thức toán đó, mang nó so sánh với các task của bạn, giờ lấy ví dụ như mình mang một hàm loss hay sử dụng bên các nhiệm vụ về hồi quy, rồi mình mang sang để làm loss function cho bài toán phân loại thì lúc này nó phản ánh không có đúng nữa.
Ví dụ như trong một bài toán phân loại nhị phân, hàm loss sử dụng thường là Binary Cross Entropy (sẽ giới thiệu phía dưới) mà mình không dùng, mình tự nhiên dùng Mean Squared Error (sẽ giới thiệu phía dưới) vốn là một hàm loss hay đi chung với nhiệm vụ hồi quy. Vấn đề xảy ra ở chỗ là MSE sẽ đối xử với các lỗi phân loại như nhau trong khi ta muốn nếu như lỗi càng lớn thì phạt càng nặng, MSE không làm chuyện đó.
Bên cạnh đó cũng có các yếu tố khác sẽ ảnh hưởng đến việc chúng ta lựa chọn hàm loss, như là các vấn đề về tính hội tụ cũng như là scale của task. À, và nó còn là vấn đề về thuật toán nữa. Ví dụ như trong machine learning, chúng ta thường sử dụng gradient-based approach để cập nhật trọng số trong mô hình do đó mà yêu cầu hàm loss phải là một hàm số khả vi, nhưng với các thuật toán heuristic approach, ví dụ cụ thể như là giải thuật di truyền, chúng ta sử dụng các hàm value function (idea tựa tựa hàm loss, idea dịch ngược lại từ hàm loss, tức là ta muốn maximize giá trị của hàm này) rồi sau đó sử dụng evolutionary search (các bước như chọn lọc, rồi lai tạo, rồi đột biến) để hướng tới kết quả tốt hơn, và do đó value function không cần phải là một hàm khả vi.
Một vấn đề khác cũng cần phải lưu tâm đó chính là phân phối của dữ liệu, ví dụ như trong bài toán phân loại nhị phân, cụ thể là trong trường hợp dữ liệu bị mất cân bằng (một class có số lượng sample thống trị số lượng sample của class còn lại), thường gặp vấn đề này là trong các vấn đề liên quan đến lừa đảo tín dụng, hoặc là dự đoán bệnh ung thư. 2 cái này là cái case kinh điển trong các bài toán có liên quan đến việc dữ liệu bị mất cân bằng. Hoặc một trường hợp khác đó là chúng ta gặp phải long-tail distribution, như là hình dưới đây:
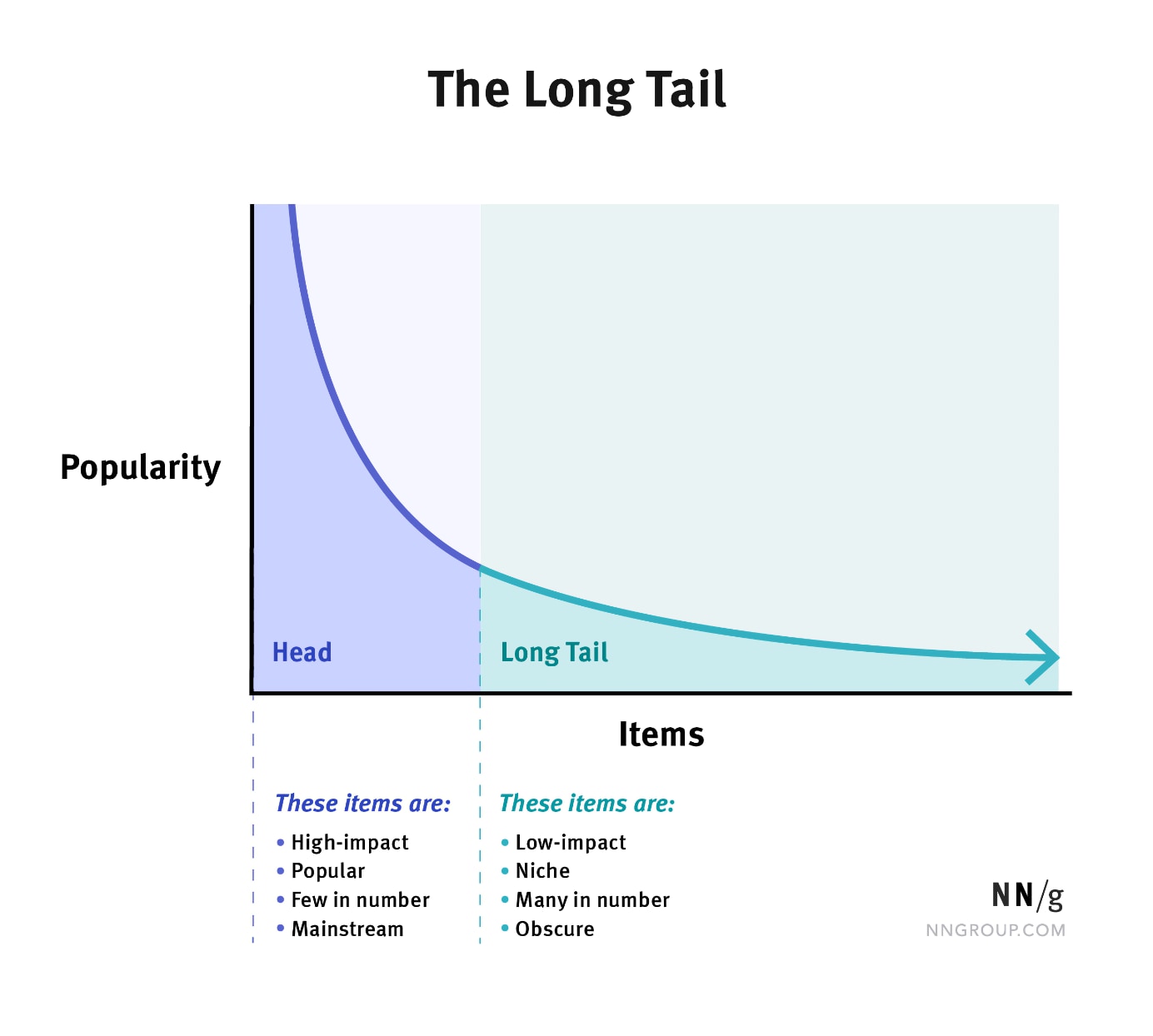
Đó, chứ không phải muốn chọn là chọn, mà sau khi chọn rồi chúng ta phải nghĩ xem chúng ta cần phải chọn metrics như thế nào cho nó phù hợp (vốn là một chủ đề khác cũng khoai không kếm.)
Không phải muốn chọn là chọn, nghĩ rồi chọn.
2.2 Các hàm loss cho bài toán phân loại
Trong học máy, các bài toán phân loại là bài toán gán cho các điểm dữ liệu một nhãn cụ thể (hoặc nhiều nhãn, tùy bài toán). Với mục tiêu cụ thể như vậy, chúng ta mong muốn giá trị trả ra bởi mô hình là một là một phân phối xác suất thể hiện khả năng mà một điểm thuộc vào một lớp bất kỳ nào đó.
2.2.1 Cross-Entropy loss
2.2.2 Hinge Loss
2.2.3 Log Loss
2.2.4 Focal Loss
Được sử dụng để giải quyết các bài toán phân loại mà ở đó dữ liệu bị mất cân bằng
2.3 Các hàm loss cho bài toán hồi quy
Ồ, ngoài ra mình thấy hàm nào được sử dụng để tính khoảng cách đều có khả năng là một hàm loss, hữu dụng không thì chưa có chắc
2.3.1 Mean Squared Error
Hay còn được biết đến là L2 Loss, là một hàm loss rất hay gặp, đơn giản, dễ dùng, hiệu quả, song vẫn có nhược điểm (đề cập sau), dưới đây là công thức:
\[\begin{equation} L(y, y') = \frac{1}{n} \sum_{i=1}^{n} (y_i - y'_i)^2 \end{equation}\]Trong đó:
- $n$ là số lượng sample trong bộ dữ liệu (hoặc batch dữ liệu)
- $y_i$ là giá trị dự đoán của mẫu thứ $i$
- $y’$ là giá trị thực của mẫu thứ $i$
Hàm loss này sẽ hoạt động vô cùng tốt nếu như phân phối của dữ liệu tuân theo phân phối chuẩn, và không có outlier.